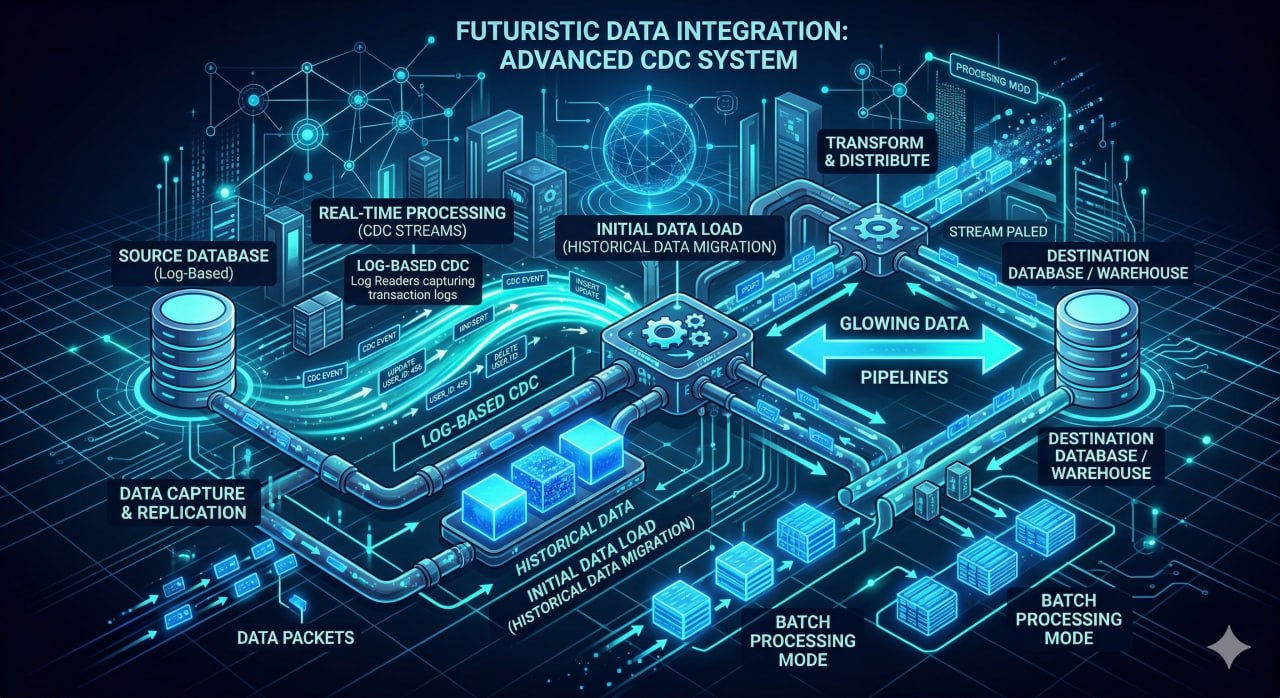
Kemampuan menangkap setiap perubahan data di sistem sumber dan mereplikasinya ke sistem tujuan secara akurat dan tepat waktu, baik secara real-time maupun batch, mendukung berbagai skenario integrasi data enterprise.
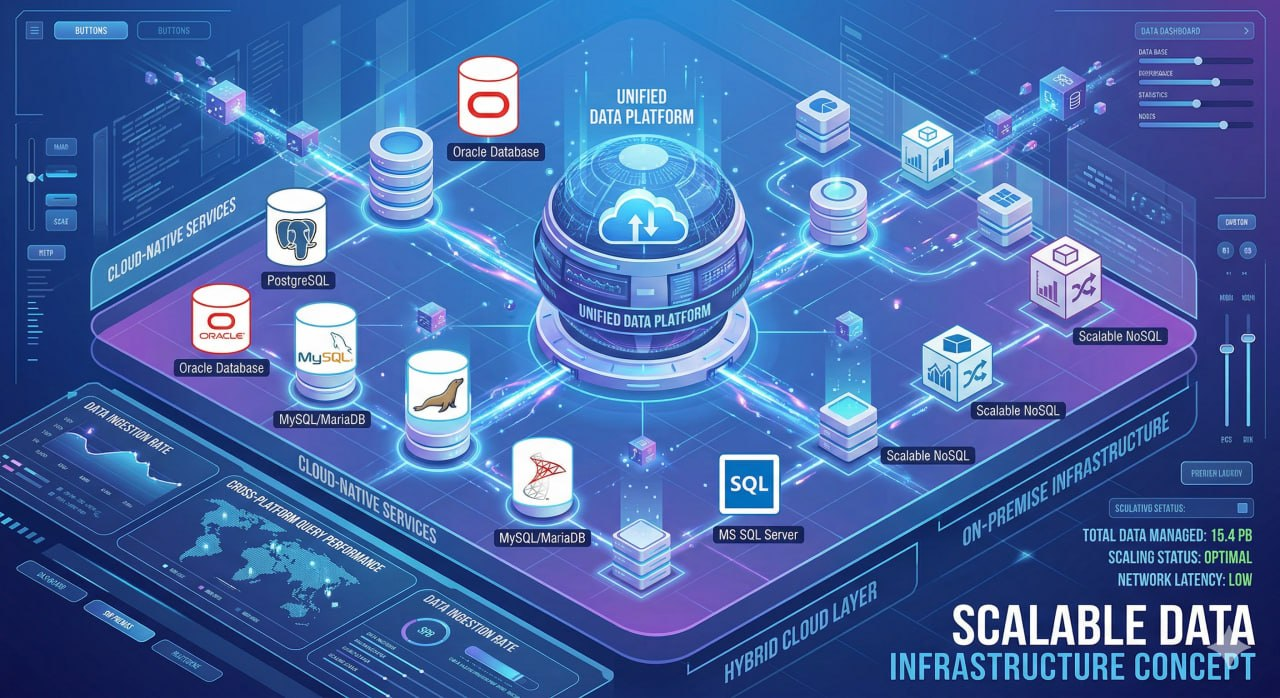
Kompatibilitas dengan berbagai sistem manajemen basis data yang umum digunakan di lingkungan enterprise pemerintahan, memastikan tidak ada sistem yang tertinggal dari ekosistem integrasi data.
Kemampuan mengubah, membersihkan, dan memperkaya data selama proses pemindahan dari sumber ke tujuan, memastikan data yang tiba di sistem tujuan sesuai format, struktur, dan kualitas yang diharapkan.
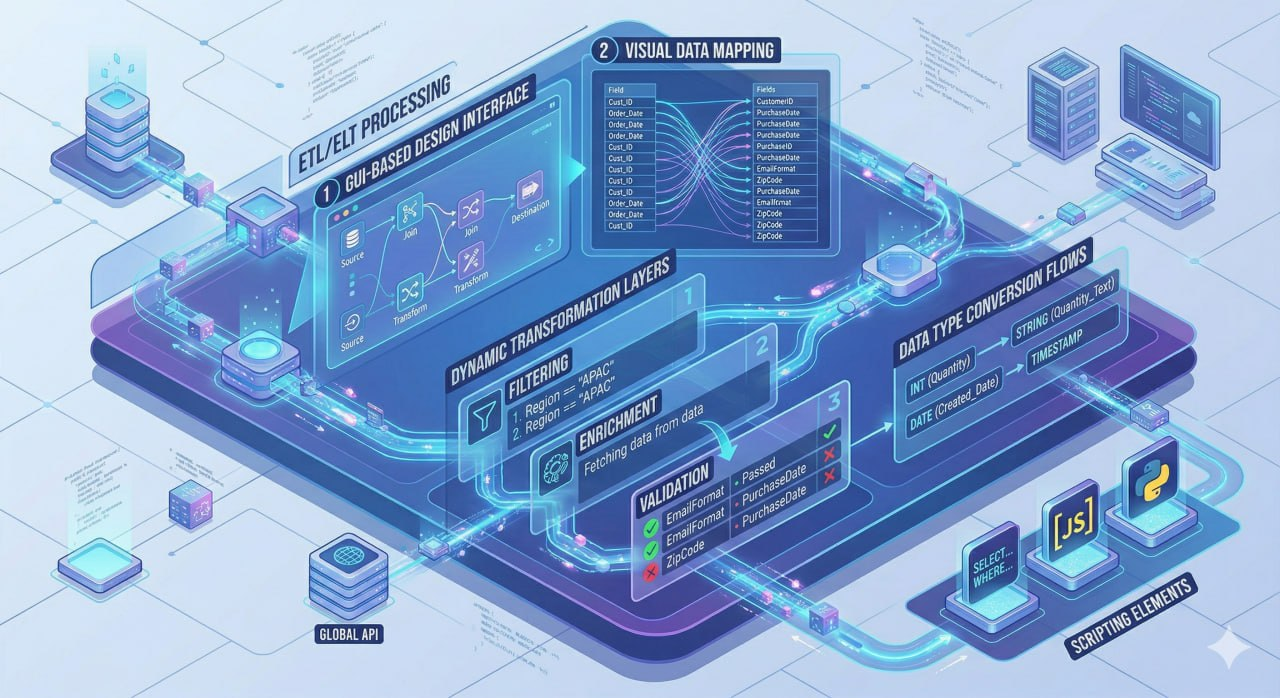
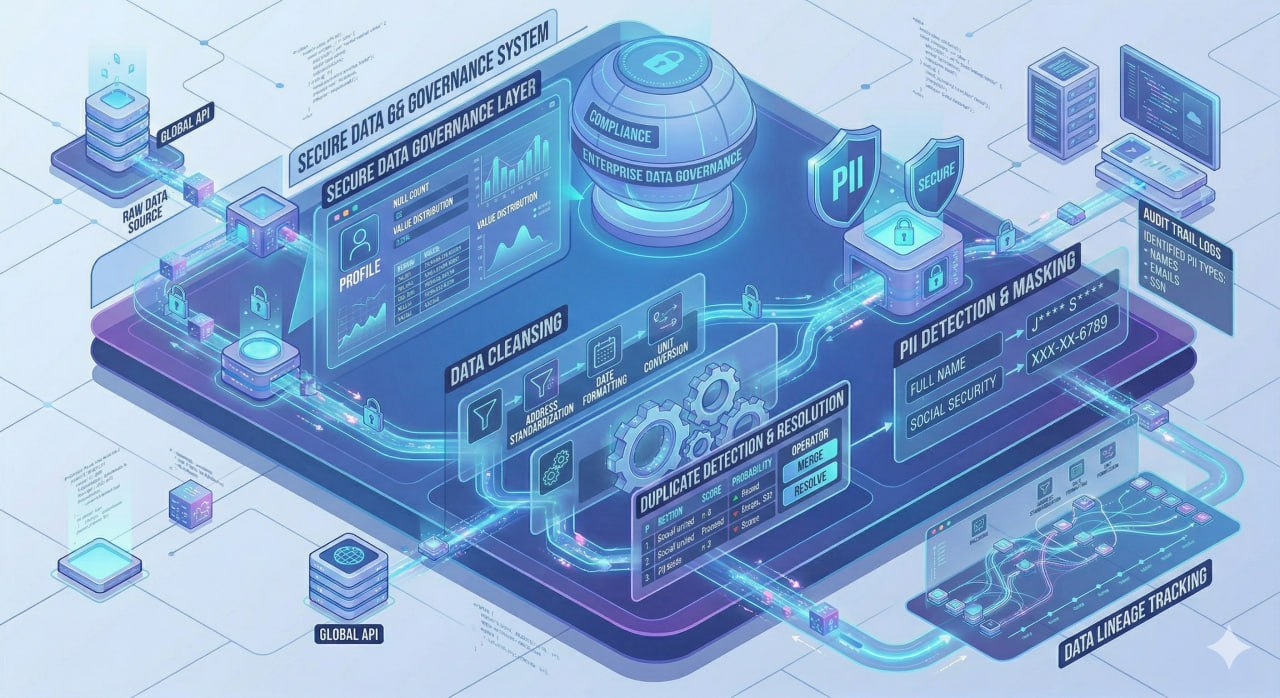
Memastikan data yang disinkronisasi akurat, lengkap, konsisten, dan sesuai dengan kebijakan tata kelola data serta regulasi privasi yang berlaku, termasuk perlindungan data pribadi sesuai UU PDP Indonesia.
Penanganan cerdas ketika data yang sama diubah secara bersamaan di dua atau lebih sistem, memastikan konsistensi data terjaga tanpa kehilangan informasi.
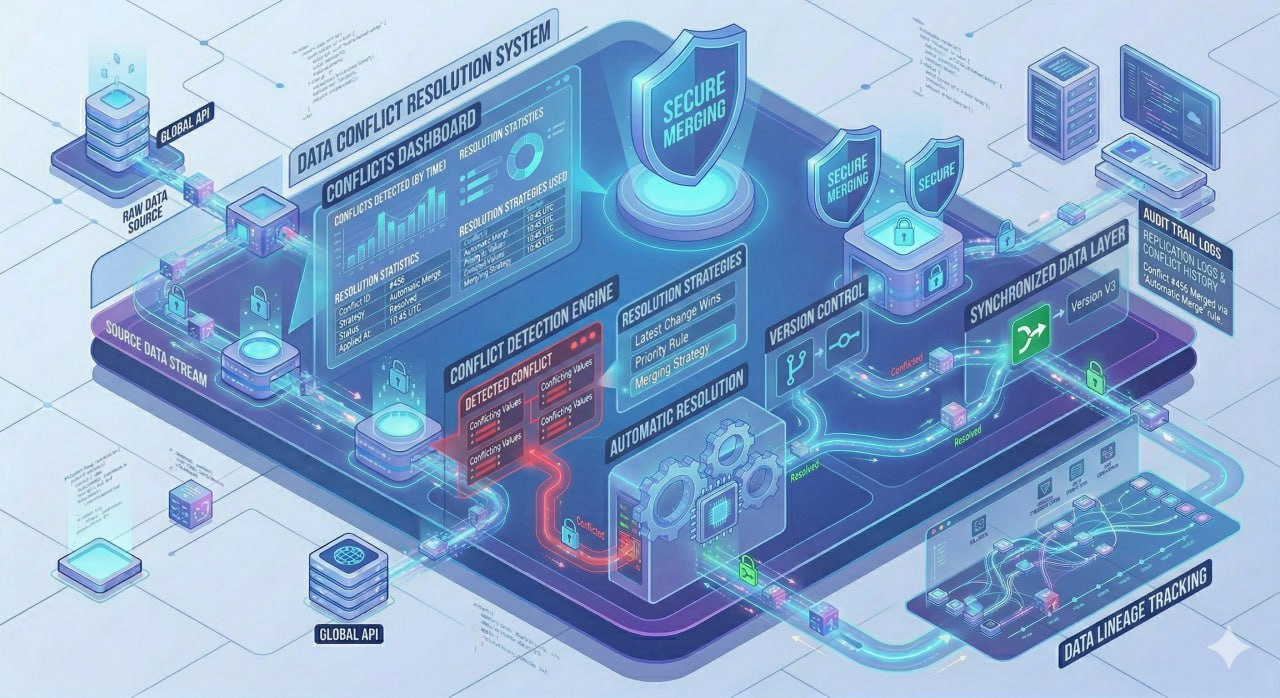
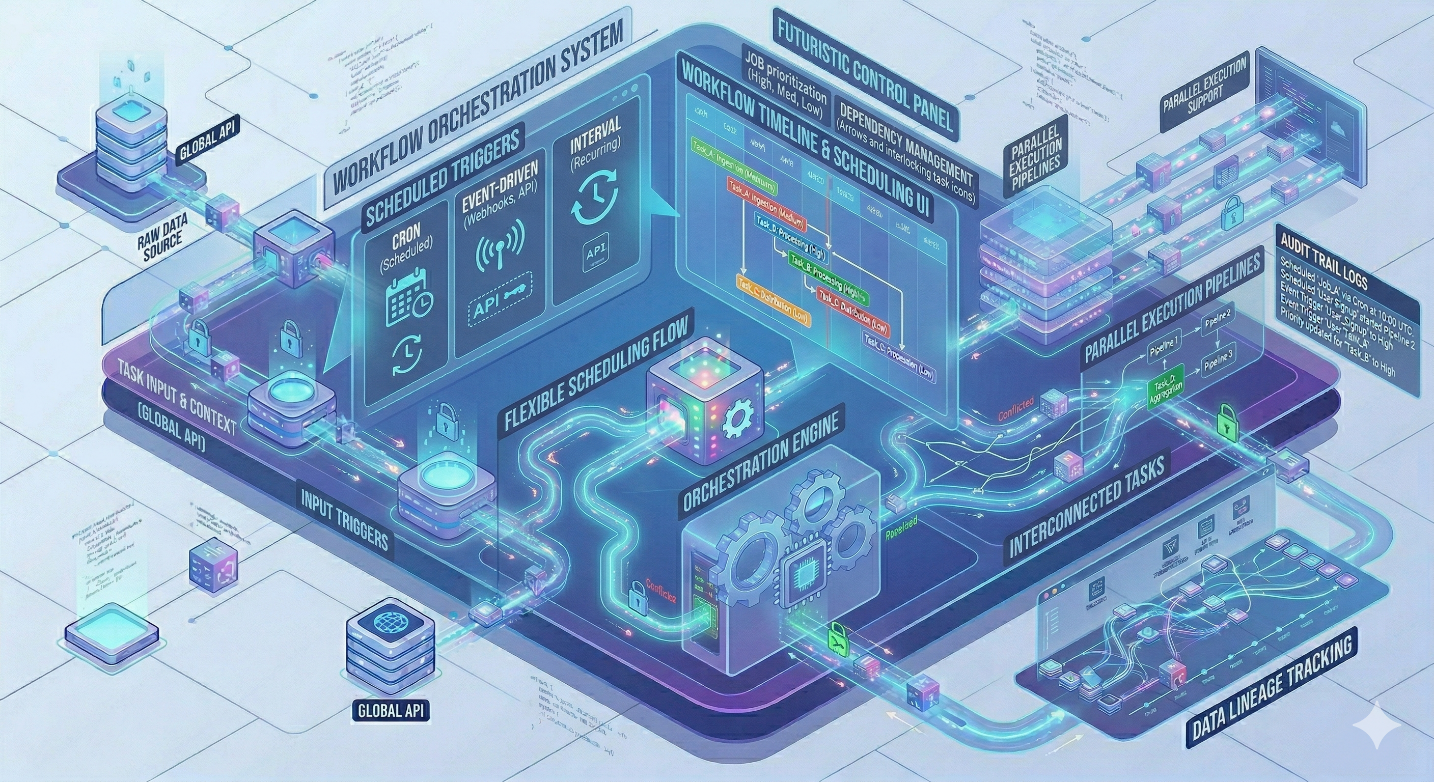
Pengaturan jadwal dan koordinasi eksekusi proses sinkronisasi data yang kompleks, memastikan pipeline data berjalan pada waktu yang tepat, dalam urutan yang benar, dengan pengelolaan prioritas dan dependensi yang cerdas.
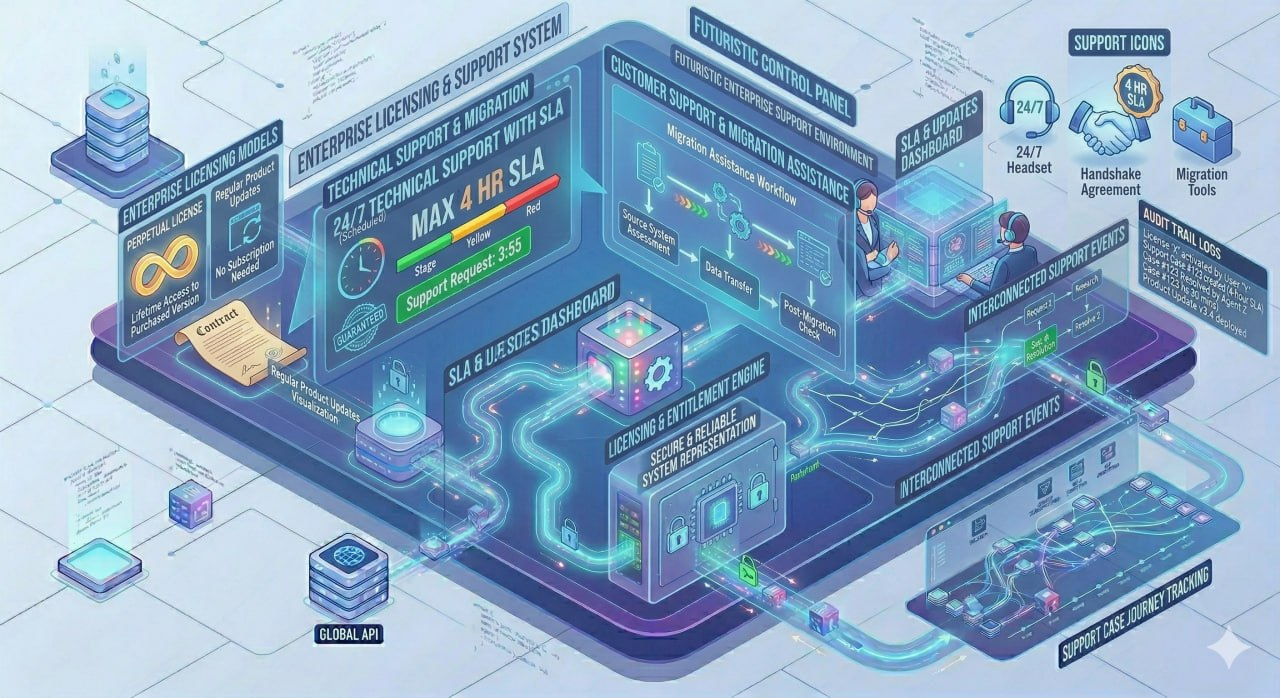
Kepastian hukum dan jaminan dukungan teknis profesional untuk Platform Sinkronisasi Data.